
Integrating Kueue with EvalHub: A Complete Guide to Production-Ready LLM Evaluation Job Management
Introduction
Section titled “Introduction”EvalHub is a service for running LLM (Large Language Model) evaluation benchmarks in Kubernetes environments. As organizations scale their AI/ML workloads, they face increasing challenges around resource management, fair sharing, and job prioritization. This is where Kueue comes in.
Kueue is a Kubernetes-native job queueing system that provides sophisticated workload management capabilities. This guide explores why and how to integrate Kueue with EvalHub to build a production-ready evaluation platform.
Why EvalHub Needs Kueue
Section titled “Why EvalHub Needs Kueue”The Challenge: Resource Contention in Shared Clusters
Section titled “The Challenge: Resource Contention in Shared Clusters”In a typical AI/ML platform deployment:
- Multiple teams run evaluation jobs simultaneously
- Limited GPU/CPU resources must be shared fairly
- Urgent evaluations (production model validation) compete with experimental evaluations (research experiments)
- Resource sprawl can lead to cluster instability or quota exhaustion
- Job failures due to insufficient resources waste time and compute
The Solution: Intelligent Workload Management
Section titled “The Solution: Intelligent Workload Management”Without Kueue, evaluation jobs compete for resources in an uncontrolled manner:

With Kueue, jobs are managed intelligently:

Key Advantages of Kueue Integration
Section titled “Key Advantages of Kueue Integration”1. Fair Resource Sharing Across Tenants
Section titled “1. Fair Resource Sharing Across Tenants”Kueue enables multi-tenancy with guaranteed quotas:
# Team A gets 50% of resourcesClusterQueue: team-a-cq CPU: 32 cores Memory: 128Gi GPU: 4
# Team B gets 50% of resourcesClusterQueue: team-b-cq CPU: 32 cores Memory: 128Gi GPU: 4Each team’s evaluation jobs stay within their quota, preventing one team from monopolizing cluster resources.
2. Priority-Based Job Scheduling
Section titled “2. Priority-Based Job Scheduling”Critical production evaluations can preempt lower-priority research jobs:
- Production model validation: High priority (1000) - must complete quickly
- Routine evaluations: Medium priority (500) - normal SLA
- Experimental benchmarks: Low priority (100) - can wait or be preempted
3. Resource Quota Enforcement
Section titled “3. Resource Quota Enforcement”Prevent runaway jobs from consuming all cluster resources:
# Quota limits per ClusterQueueresources: - name: cpu nominalQuota: 32 - name: memory nominalQuota: 128Gi - name: nvidia.com/gpu nominalQuota: 44. Automatic Queueing and Admission
Section titled “4. Automatic Queueing and Admission”Jobs that don’t fit current quota are automatically queued rather than failing:
- Without Kueue: Job fails with “Insufficient resources” → Manual retry
- With Kueue: Job queued automatically → Admitted when resources available
5. Cohort-Based Resource Borrowing
Section titled “5. Cohort-Based Resource Borrowing”Teams can borrow unused quota from other teams within the same cohort.
6. Visibility into Job Queue Status
Section titled “6. Visibility into Job Queue Status”Track why jobs are pending and their position in the queue:
kubectl get localqueue -n team-aNAME CLUSTERQUEUE PENDING ADMITTEDlocal-queue team-a-cq 3 5
kubectl get workload -n team-aNAME QUEUE ADMITTED AGEeval-job-1-abc123 local-queue True 2meval-job-2-def456 local-queue False 30s # Waiting in queueUnderstanding the Personas
Section titled “Understanding the Personas”Kueue integration involves three key personas, each with distinct responsibilities:
1. Cluster Administrator
Section titled “1. Cluster Administrator”Role: Manages the Kubernetes cluster and Kueue installation
Responsibilities:
- Install and configure Kueue operator
- Create ClusterQueues and ResourceFlavors
- Define cluster-wide preemption policies
- Set up multi-tenancy boundaries
- Monitor cluster-wide resource utilization
Scope: Cluster-wide
2. Namespace Owner / Team Lead
Section titled “2. Namespace Owner / Team Lead”Role: Manages resources for a specific team/namespace
Responsibilities:
- Create LocalQueues in team namespaces
- Map LocalQueues to appropriate ClusterQueues
- Configure namespace labels for Kueue management
- Monitor team’s quota usage
Scope: Namespace-specific
3. EvalHub User / ML Engineer
Section titled “3. EvalHub User / ML Engineer”Role: Submits evaluation jobs via EvalHub API
Responsibilities:
- Specify queue name when creating evaluation jobs
- Understand job queueing and preemption behavior
- Monitor job status through EvalHub API or kubectl
Scope: Individual jobs
Setup Guide by Persona
Section titled “Setup Guide by Persona”Cluster Administrator: Installing and Configuring Kueue
Section titled “Cluster Administrator: Installing and Configuring Kueue”Step 1: Install Kueue Operator, create kueue cluster instance and ResourceFlavors.
Section titled “Step 1: Install Kueue Operator, create kueue cluster instance and ResourceFlavors.”Step 2: Create ClusterQueues for Multi-Tenancy (‘team-a-cq’/‘team-b-cq’ in respective namespaces, referenced in examples below)
Section titled “Step 2: Create ClusterQueues for Multi-Tenancy (‘team-a-cq’/‘team-b-cq’ in respective namespaces, referenced in examples below)”Namespace Owner: Setting Up Team Resources
Section titled “Namespace Owner: Setting Up Team Resources”Step 1: Label the Namespace
Section titled “Step 1: Label the Namespace”Important labels:
team=team-a- Matches the ClusterQueue’s namespaceSelectorkueue.openshift.io/managed=true- Enables Kueue managementevalhub.trustyai.opendatahub.io/tenant=true- EvalHub tenant marker
Step 2: Create LocalQueue
Section titled “Step 2: Create LocalQueue”The LocalQueue connects your namespace to the ClusterQueue:
apiVersion: kueue.x-k8s.io/v1beta2kind: LocalQueuemetadata: name: eval-queue namespace: team-a-namespacespec: clusterQueue: team-a-cq # References the ClusterQueue created by adminEvalHub User: Submitting Jobs with Kueue
Section titled “EvalHub User: Submitting Jobs with Kueue”Job Submission via API
Section titled “Job Submission via API”Jobs submitted via EvalHub API get assigned priority 0 by default:
curl --request POST \ --url https://evalhub-team-a.example.com/api/v1/evaluations/jobs \ --header 'Authorization: Bearer <token>' \ --header 'Content-Type: application/json' \ --data '{ "name": "standard-eval", "model": { "url": "http://llm-service.team-a.svc.cluster.local:8080/v1", "name": "granite-3.1-8b" }, "queue": { "kind": "kueue", "name": "eval-queue" }, "benchmarks": [ { "id": "mmlu", "provider_id": "lm_evaluation_harness", "parameters": { "num_fewshot": 5 } } ]}'Result: Job queued with priority 0, admitted when quota available.
Checking Job Queue Status
Section titled “Checking Job Queue Status”Via EvalHub API:
curl --request GET \ --url https://evalhub-team-a.example.com/api/v1/evaluations/jobs/<resource-id> \ --header 'Authorization: Bearer <token>'Response:
{ "resource": { "id": "abc123-def456-...", "created_at": "2026-04-13T10:30:00Z" }, "status": { "state": "pending", "message": { "message": "Evaluation job created", "message_code": "evaluation_job_created" } }}Note: EvalHub API currently shows high-level states only:
pending- Job created but not yet admittedrunning- Job admitted and executingcompleted- Job finished
Via Kubernetes (for detailed status):
# Find the Kubernetes JobJOB_NAME=$(kubectl get jobs -n team-a-namespace | grep "$RESOURCE_ID" | awk '{print $1}')
# Check job statuskubectl get job "$JOB_NAME" -n team-a-namespace
# Check workload status (shows queue position, preemption, etc.)WORKLOAD=$(kubectl get workloads -n team-a-namespace -o json | \ jq -r ".items[] | select(.metadata.ownerReferences[].name == \"$JOB_NAME\") | .metadata.name")
kubectl get workload "$WORKLOAD" -n team-a-namespace -o yamlUnderstanding Preemption in Evaluation Jobs
Section titled “Understanding Preemption in Evaluation Jobs”Preemption is a critical concept when using Kueue. Here’s what every persona needs to know:
What is Preemption?
Section titled “What is Preemption?”Preemption occurs when a higher-priority job needs resources but the cluster is at quota. Kueue will:
- Suspend (stop) a lower-priority running job
- Terminate its pod(s)
- Admit the higher-priority job
- Requeue the preempted job
- Resume the preempted job when resources become available
Default Preemption Behavior
Section titled “Default Preemption Behavior”When you create a ClusterQueue without specifying preemption settings:
# Default behavior (no preemption section specified)apiVersion: kueue.x-k8s.io/v1beta2kind: ClusterQueuemetadata: name: my-queuespec: resourceGroups: [...] # preemption not specifiedDefaults applied:
preemption: withinClusterQueue: Never # No preemption within queue reclaimWithinCohort: Never # Can't reclaim from cohort borrowWithinCohort: policy: Never # Can't preempt when borrowingBehavior: Jobs queue in FIFO order. No preemption occurs, even if you assign different priorities to jobs.
Enabling Preemption
Section titled “Enabling Preemption”To enable priority-based preemption:
apiVersion: kueue.x-k8s.io/v1beta2kind: ClusterQueuemetadata: name: my-queuespec: preemption: withinClusterQueue: LowerPriority # Enable preemption resourceGroups: [...]Behavior: Higher-priority jobs can preempt lower-priority jobs within the same ClusterQueue.
Where is Preemption Status Reported?
Section titled “Where is Preemption Status Reported?”Understanding where to look for preemption information is crucial for debugging:
1. Kubernetes Workload Resource (Most Detailed)
Section titled “1. Kubernetes Workload Resource (Most Detailed)”The Workload resource contains comprehensive preemption information:
kubectl get workload <workload-name> -n <namespace> -o yamlKey ‘status.conditions’ to check:
When preempted: ‘Admitted’ will be ‘False’ and ‘Evicted’/‘Preempted’/‘Requeued’ will be ‘True’.
After resume: ‘Admitted’ will be ‘True’, ‘Requeued’ will be true and ‘Evicted’/‘Preempted’ will be ‘False’.
Important: The Requeued condition remains True even after resume, preserving the history that the job was preempted.
2. Kubernetes Job Resource (Basic)
Section titled “2. Kubernetes Job Resource (Basic)”The Job resource shows suspension status only:
kubectl get job <job-name> -n <namespace> -o yamlstatus: conditions: # When preempted: - type: Suspended status: "True" reason: JobSuspended message: "Job suspended"
# After resume: - type: Suspended status: "False" reason: JobResumed message: "Job resumed"Limitation: The Job resource does NOT include:
- Why it was suspended (preemption vs manual suspension)
- Which job caused the preemption
- Preemption UIDs or paths
3. Kubernetes Events
Section titled “3. Kubernetes Events”Events provide a timeline:
kubectl get events -n <namespace> --sort-by='.lastTimestamp' | grep <job-name>Typical event sequence:
7m30s Normal QuotaReserved workload Quota reserved in ClusterQueue7m30s Normal Admitted workload Admitted by ClusterQueue6m55s Normal EvictedDueToPreempted workload Preempted to accommodate workload (UID: ...)6m55s Normal Preempted workload Preempted to accommodate workload (UID: ...)6m55s Normal Suspended job Job suspended6m55s Normal Stopped job Preempted to accommodate workload (UID: ...)5m50s Normal Resumed job Job resumed5m49s Normal QuotaReserved workload Quota reserved in ClusterQueue (after waiting 65s)5m49s Normal Admitted workload Admitted by ClusterQueue4. EvalHub API Response (Minimal)
Section titled “4. EvalHub API Response (Minimal)”Current limitation: The EvalHub API does not expose Kueue-specific states like preemption or requeueing.
{ "status": { "state": "pending", // High-level only: pending, running, completed "message": { "message": "Evaluation job created" } }}To track preemption for EvalHub jobs:
- Get the
resource.idfrom the API response - Find the Kubernetes Job (name contains the resource ID)
- Find the associated Workload resource
- Check Workload
status.conditionsfor detailed preemption info
Example:
RESOURCE_ID="abc123-def456-..."
# Find JobJOB_NAME=$(kubectl get jobs -n team-a-namespace | grep "$RESOURCE_ID" | awk '{print $1}')
# Find WorkloadWORKLOAD=$(kubectl get workloads -n team-a-namespace -o json | \ jq -r ".items[] | select(.metadata.ownerReferences[].name == \"$JOB_NAME\") | .metadata.name")
# Check for preemptionkubectl get workload "$WORKLOAD" -n team-a-namespace -o jsonpath='{.status.conditions}' | \ jq '.[] | select(.type == "Preempted" or .type == "Evicted" or .type == "Requeued")'Impact on Evaluation Results
Section titled “Impact on Evaluation Results”Critical consideration: When a job is preempted and resumed, it restarts from the beginning.
What this means:

Implications:
- No progress is saved - The job doesn’t checkpoint its state
- Total runtime includes preemption time - Job age includes suspension period
- Unpredictable completion times - Jobs may be preempted multiple times
Best practice:
- Create a dedicated ClusterQueue for evaluation jobs and disable preemption (
withinClusterQueue: Never) to ensure jobs complete without interruption, as evaluation workloads cannot checkpoint their progress and restart from the beginning when resumed after preemption.
Job Lifecycle with Kueue
Section titled “Job Lifecycle with Kueue”Understanding the complete job lifecycle helps with monitoring and troubleshooting.
Normal Flow (No Preemption)
Section titled “Normal Flow (No Preemption)”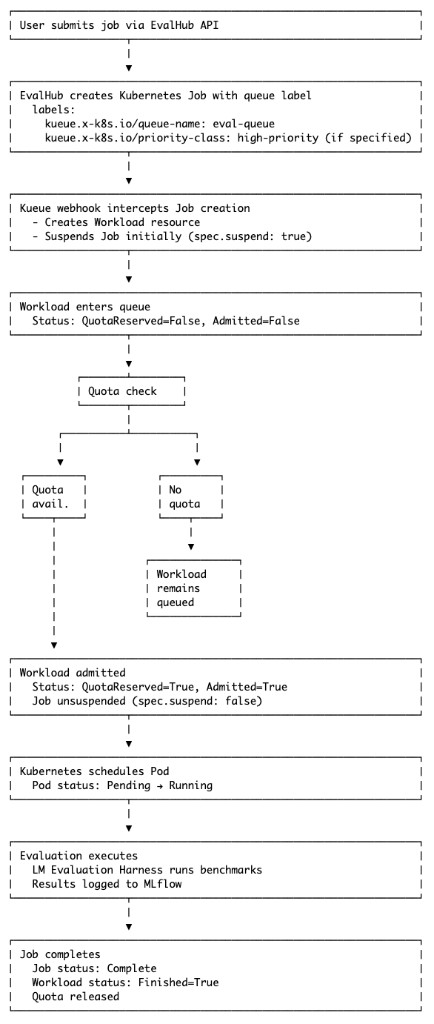
Preemption Flow
Section titled “Preemption Flow”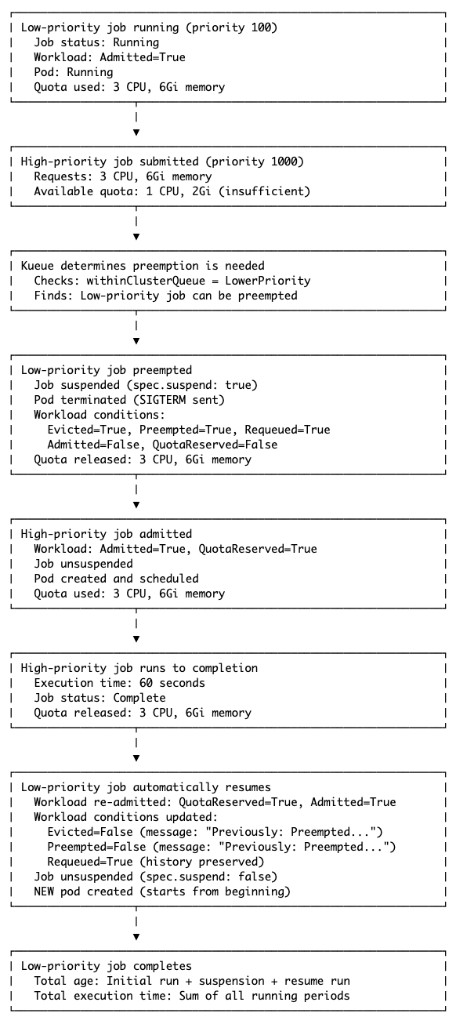
Monitoring and Troubleshooting
Section titled “Monitoring and Troubleshooting”Common Scenarios and How to Debug
Section titled “Common Scenarios and How to Debug”Scenario 1: Job Stuck in Pending
Section titled “Scenario 1: Job Stuck in Pending”Symptom:
kubectl get job my-eval-job -n team-a-namespace# NAME STATUS COMPLETIONS AGE# my-eval-job Suspended 0/1 5mDiagnosis:
# Check workload statusWORKLOAD=$(kubectl get workloads -n team-a-namespace -o json | \ jq -r ".items[] | select(.metadata.ownerReferences[].name == \"my-eval-job\") | .metadata.name")
kubectl get workload "$WORKLOAD" -n team-a-namespace -o jsonpath='{.status.conditions}' | \ jq '.[] | select(.type == "QuotaReserved" or .type == "Admitted")'Possible causes:
-
Insufficient quota:
{"type": "QuotaReserved","status": "False","reason": "Pending","message": "couldn't assign flavors to pod set main: insufficient unused quota for cpu in flavor default-flavor, 8 more needed"}Solution: Wait for quota to free up, or request quota increase from cluster admin.
-
Invalid queue name:
Terminal window kubectl get workload "$WORKLOAD" -n team-a-namespace# NAME QUEUE RESERVED IN ADMITTED# job-my-eval-job-abc12 non-existent-queue FalseSolution: Check LocalQueue exists, verify queue name in job specification.
-
Waiting for higher-priority jobs:
Terminal window kubectl get workloads -n team-a-namespace --sort-by=.spec.prioritySolution: Increase job priority or wait for queue to clear.
Scenario 2: Job Was Preempted
Section titled “Scenario 2: Job Was Preempted”Symptom:
kubectl get job my-eval-job -n team-a-namespace# NAME STATUS COMPLETIONS AGE# my-eval-job Suspended 0/1 10mDiagnosis:
# Check for preemptionkubectl get workload "$WORKLOAD" -n team-a-namespace -o jsonpath='{.status.conditions}' | \ jq '.[] | select(.type == "Preempted" or .type == "Evicted")'Output:
{ "type": "Preempted", "status": "True", "reason": "InClusterQueue", "message": "Preempted to accommodate a workload (UID: 641031a6-be4d-43f5-b51f-24a4d05dffe6, JobUID: 1f1c675a-711f-4a13-a3bd-da3d50e6f893)"}Solution:
- Wait for preemptor to complete (job will auto-resume)
- Or increase your job’s priority to avoid future preemption
Scenario 3: Job Running But Progress Unknown
Section titled “Scenario 3: Job Running But Progress Unknown”Symptom: Job has been running for a while, but you want to check if it’s making progress.
Check if pod was restarted (preemption):
kubectl get pod "$POD" -n team-a-namespace -o jsonpath='{.status.containerStatuses[0].restartCount}'# 0 (no restarts)
# Check pod age vs job agekubectl get pod "$POD" -n team-a-namespace -o jsonpath='{.metadata.creationTimestamp}'kubectl get job my-eval-job -n team-a-namespace -o jsonpath='{.metadata.creationTimestamp}'
# If pod is much newer than job, it was likely preempted and recreatedUseful Monitoring Commands
Section titled “Useful Monitoring Commands”# View all queued workloadskubectl get workloads -n team-a-namespace
# View quota usagekubectl get clusterqueue team-a-cq -o yaml | grep -A 20 "flavorsUsage:"
# View pending workloads countkubectl get localqueue eval-queue -n team-a-namespace
# Get workload eventskubectl get events -n team-a-namespace --field-selector involvedObject.kind=Workload
# View all preempted workloadskubectl get workloads -n team-a-namespace -o json | \ jq -r '.items[] | select(.status.conditions[]? | select(.type == "Preempted" and .status == "True")) | .metadata.name'Conclusion
Section titled “Conclusion”Integrating Kueue with EvalHub transforms ad-hoc evaluation job execution into a managed, fair, and efficient system. By understanding the roles of each persona and following the best practices outlined in this guide, organizations can:
- Prevent resource contention through quota enforcement
- Enable fair sharing across multiple teams
- Prioritize critical work with intelligent preemption
- Increase cluster utilization through cohort-based borrowing
- Improve visibility into job queueing and resource usage
Resources
Section titled “Resources”- Kueue Documentation: https://kueue.sigs.k8s.io/
- EvalHub Documentation: https://eval-hub.github.io/
- Kubernetes Job Documentation: https://kubernetes.io/docs/concepts/workloads/controllers/job/
Version: 1.0
Last Updated: April 2026
Feedback: Please submit issues or suggestions to the platform team